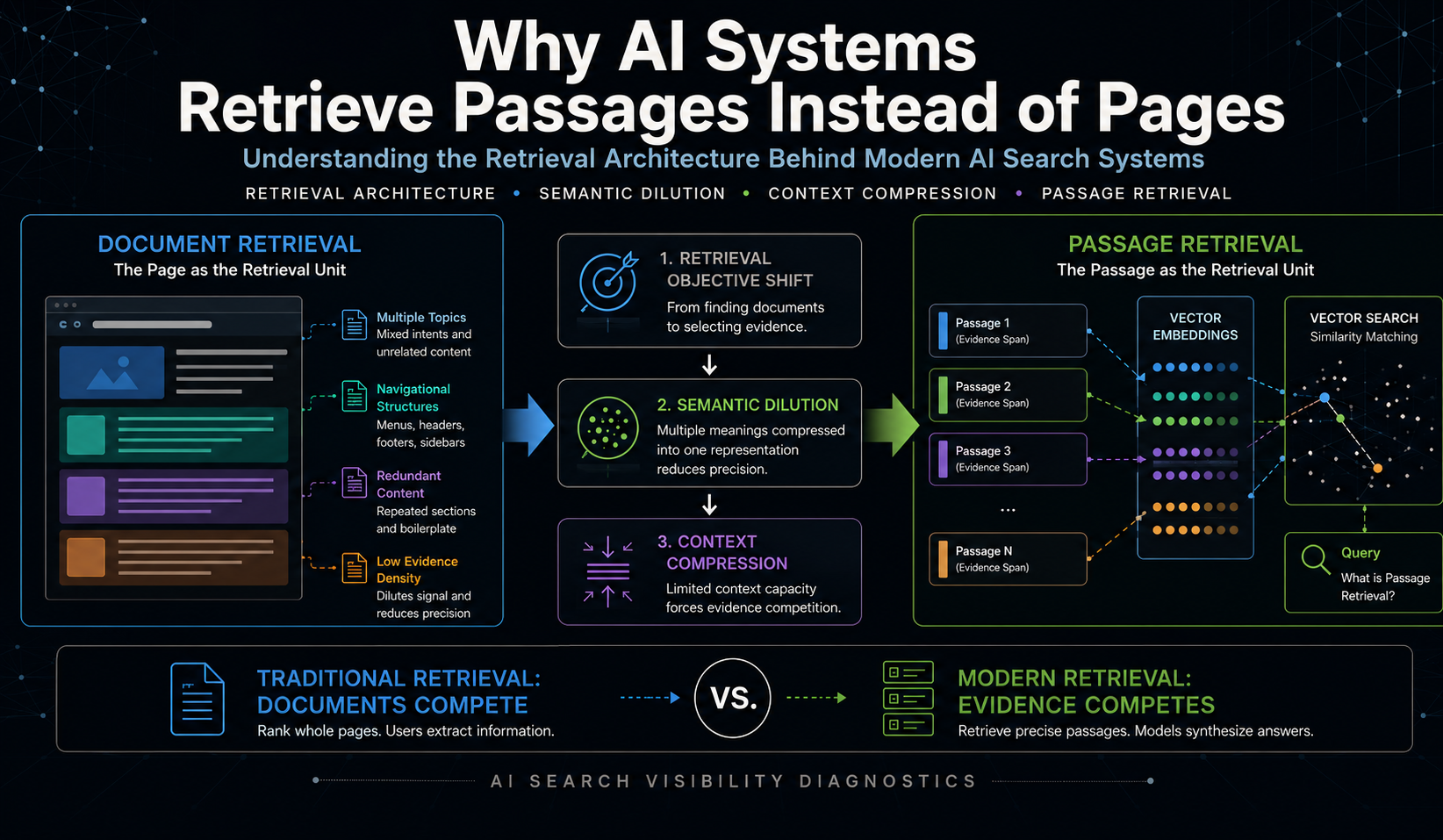
The Retrieval Shift From Pages To Passages
AI systems retrieve passages instead of pages because large language models generate answers under constrained context windows, finite attention allocation, and limited synthesis capacity. Entire documents often contain multiple topics, navigational structures, redundant context, and semantically unrelated content that reduce retrieval efficiency inside generation pipelines. Modern retrieval architectures therefore increasingly isolate Passage Retrieval Units, Evidence Spans, and implementation-specific retrievable chunks that provide higher Evidence Density and stronger query alignment than Document Retrieval Units. As retrieval systems become upstream infrastructure for synthesis systems rather than navigational systems, retrieval optimization shifts from Document Retrieval Visibility toward Evidence Selection. This transition explains why Passage Retrieval has increasingly replaced full-page retrieval as the dominant operational unit inside modern AI retrieval pipelines.
Traditional search systems were built around a relatively stable assumption:
The page functioned as the primary Document Retrieval Unit.
Search engines indexed documents, ranked URLs, and evaluated relevance primarily at the document level through systems such as BM25, TF-IDF, PageRank, and link-based authority scoring. A page functioned as a coherent Document Retrieval Unit. The search engine’s responsibility was to locate the most relevant document; the user’s responsibility was to extract the relevant information from inside it.
Modern AI retrieval systems increasingly operate under a different constraint structure.
Large language models are not primarily designed to deliver ranked lists of documents. They are designed to synthesize responses from retrieved Evidence. This changes retrieval behavior fundamentally. Instead of optimizing only for document discoverability, modern retrieval systems increasingly optimize for Evidence Selection inside constrained synthesis pipelines.
As retrieval becomes upstream infrastructure for generation systems, the Retrieval Unit, the architectural object selected for retrieval, begins to change.
Rather than retrieving entire Document Retrieval Units, modern AI systems increasingly isolate:
-
Passage Retrieval Units
-
Evidence Spans
-
localized Evidence
-
implementation-specific retrievable chunks
These smaller Retrieval Units are not merely formatting decisions. They emerge from operational pressures inside modern retrieval architectures.
A full webpage often contains:
-
multiple topics
-
mixed intents
-
navigational structures
-
redundant context
-
low Evidence Density semantic regions
-
semantically unrelated sections
Traditional search systems tolerated this because humans could navigate documents manually after retrieval. Retrieval systems only needed to surface potentially relevant pages.
Generative systems operate differently.
A synthesis system cannot efficiently process thousands of irrelevant tokens while simultaneously preserving grounding quality, context efficiency, retrieval precision, and response reliability. Retrieved information now competes for limited context allocation inside generation pipelines. Every irrelevant section consumes attention budget that could otherwise be allocated toward higher-density Evidence.
This shifts retrieval pressure away from:
“Which page is most relevant?”
toward:
“Which Evidence Span is most usable inside synthesis systems?”
The consequence is architectural.
Modern retrieval pipelines increasingly behave less like systems operating on Document Retrieval Units and more like evidence-compression systems. Information is segmented, isolated, retrieved, filtered, and selectively inserted into generation contexts as Passage Retrieval Units, implemented through retrievable chunks rather than complete Document Retrieval Units.
The page no longer behaves as the guaranteed operational unit of retrieval.
Instead, retrieval systems increasingly prioritize the extraction of localized Evidence capable of surviving:
-
retrieval constraints
-
context limitations
-
candidate competition
-
synthesis allocation
This creates the central infrastructure question explored throughout the article:
Why did full-page retrieval become operationally insufficient for modern AI systems?
Executive Summary
Modern AI retrieval systems increasingly retrieve passages rather than entire pages because the dominant objective of retrieval has shifted from document navigation toward Evidence Selection. Traditional search systems treated webpages as the primary Document Retrieval Unit because users performed information extraction manually after retrieval. As generative retrieval systems emerged, retrieval increasingly became responsible for supplying precise Evidence that could survive downstream synthesis processes.
This transition exposed two major architectural pressures. Semantic Dilution occurs when multiple meanings are compressed into a single retrieval representation, reducing retrieval precision. Context Compression occurs when finite synthesis capacity forces retrieved information to compete for limited representational space. Together, these pressures reduce the effectiveness of document-level retrieval architectures.
Passage Retrieval emerged as the architectural response. By allowing localized Semantic Regions to compete independently, retrieval systems improve Evidence Density, retrieval precision, and synthesis compatibility. Modern retrieval architectures therefore increasingly operate as evidence-selection infrastructures where Passage Retrieval Units, rather than pages, become the dominant operational Retrieval Unit.
Table of Contents
Introduction: The Retrieval Shift From Pages To Passages
Executive Summary
Why Did Traditional Search Systems Treat Entire Pages As Retrieval Units?
How Did Generative AI Systems Change The Retrieval Objective?
Why Does Whole-Page Retrieval Cause Semantic Dilution In Dense Retrieval Systems?
How Do Context Window Constraints Make Whole-Page Retrieval Operationally Inefficient?
How Does Passage Retrieval Architecture Differ From Document Retrieval?
Key Takeaways
Conclusion: The Shift to Passage Retrieval
Frequently Asked Questions
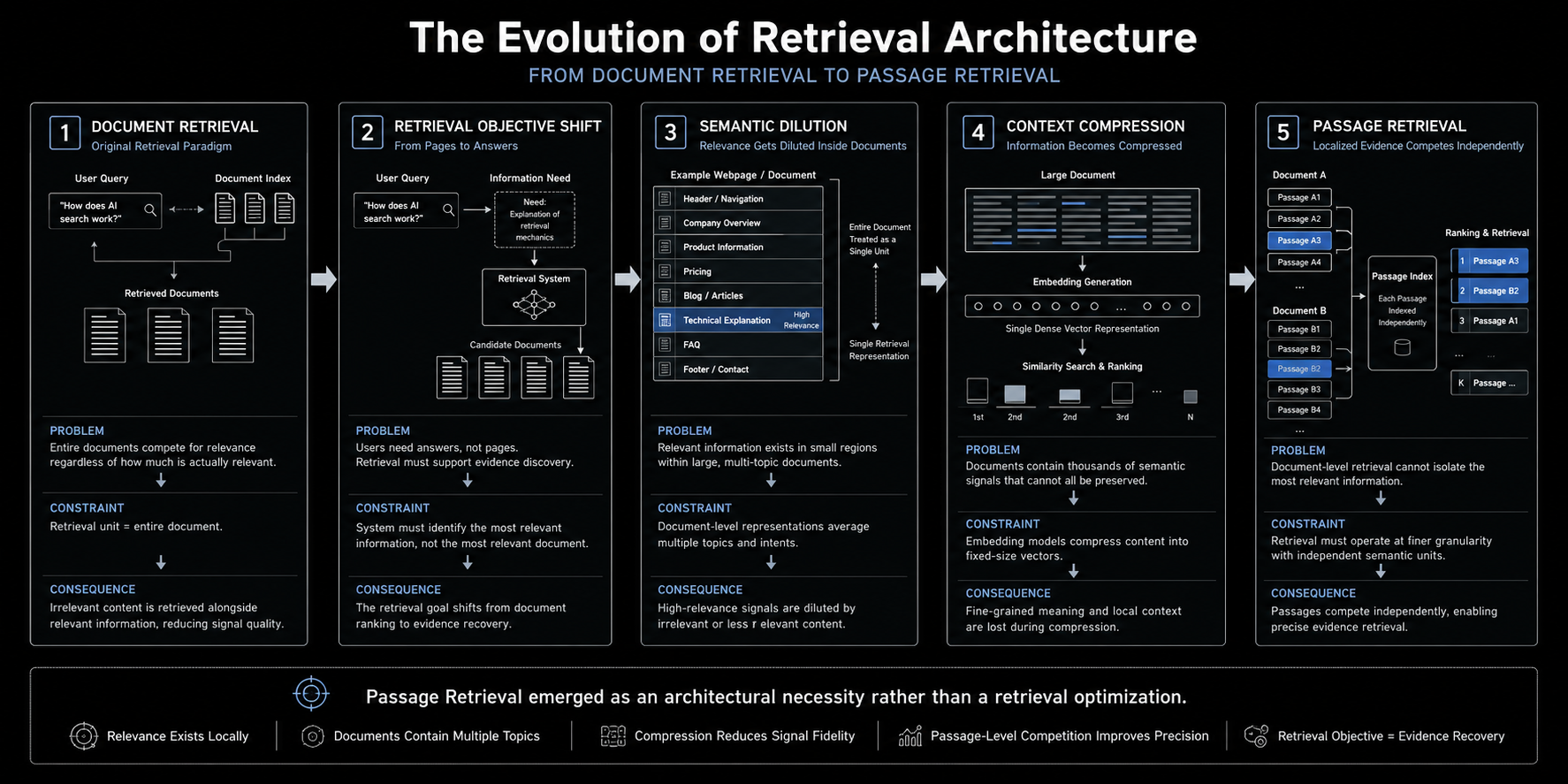
Why Did Traditional Search Systems Treat Entire Pages As Retrieval Units?
Traditional search systems treated entire pages as Document Retrieval Units because webpages represented the most stable, indexable, and computationally manageable retrieval entities available within the early web graph. Information retrieval systems such as TF-IDF and later BM25 evaluated relevance at the document level, estimating how strongly a query matched the lexical composition of a complete page rather than an individual passage. PageRank reinforced this architecture by assigning authority through page-level link relationships, making Document Retrieval Units the primary objects of ranking, retrieval, and navigation. Under this model, retrieval systems were optimized to surface relevant Document Retrieval Units, not isolate specific Evidence or Evidence Spans. Once a page was retrieved, Evidence Extraction remained a human responsibility, with users interpreting context, locating relevant sections, and synthesizing answers manually. This document-centric architecture remained operationally effective because retrieval terminated at navigation rather than downstream synthesis.
Before modern retrieval systems became tightly coupled to generative models, web search operated on a fundamentally document-centric architecture.
The page functioned as the primary Document Retrieval Unit.
Search engines indexed webpages, assigned relevance scores to complete documents, and returned ranked URLs through Search Engine Results Pages (SERPs). Under this paradigm, the Document Retrieval Unit functioned as the independently retrievable entity used for indexing, ranking, and navigation.
This architecture emerged from the operational structure of the early web itself.
The web was organized around linked documents and stable URLs. Crawlers discovered pages, parsers extracted textual content, and indexing systems transformed those pages into searchable lexical representations. Retrieval infrastructure therefore evolved around document-level indexing because pages represented the most stable and computationally manageable Document Retrieval Units available inside the web graph.
Traditional information retrieval systems such as TF-IDF and later BM25 evaluated relevance primarily at the document level. The significance of these systems was architectural rather than algorithmic: retrieval competition occurred between Document Retrieval Units, while TF-IDF and BM25 operationalized that architectural constraint through lexical relevance estimation.
PageRank introduced another major retrieval signal: authority estimation through link analysis.
Rather than evaluating only textual relevance, PageRank operationalized page-level authority estimation within the existing Document Retrieval architecture. Retrieval systems therefore ranked and surfaced documents not only through lexical relevance but also through page-level authority, further strengthening the page as the dominant Document Retrieval Unit throughout the search stack.
The architecture optimized around:
-
document discoverability
-
URL ranking
-
navigational efficiency
-
lexical relevance estimation
-
document-level authority
Importantly, these systems were designed for Document Retrieval rather than Evidence Extraction.
The operational objective of traditional search infrastructure was not to isolate the exact sentence answering a query. The system’s responsibility ended once the most relevant Document Retrieval Unit was surfaced.
Evidence Extraction remained a human task.
Users opened documents, scanned headings, interpreted surrounding context, compared sources, and manually located the relevant Evidence inside the retrieved page. Search engines improved this navigational process through snippets, metadata, and ranking systems, but the cognitive extraction layer remained external to retrieval itself.
This made document-level retrieval operationally effective for decades.
Pages were treated as sufficiently self-contained Semantic Regions whose aggregate lexical signals, topical focus, and authority characteristics provided a workable approximation of relevance. Retrieval infrastructure therefore evolved around the assumption that Document Retrieval Units functioned as coherent containers of retrievable Evidence, making page-level retrieval both operationally rational and computationally efficient.
That assumption became deeply embedded across the entire search stack.
Indexes were organized around documents. Ranking systems scored documents. Link authority accumulated at the page and domain level. SERPs displayed documents as destination objects for navigation.
The hidden dependency inside this architecture:
retrieval systems located Document Retrieval Units,
while humans performed Evidence Extraction.
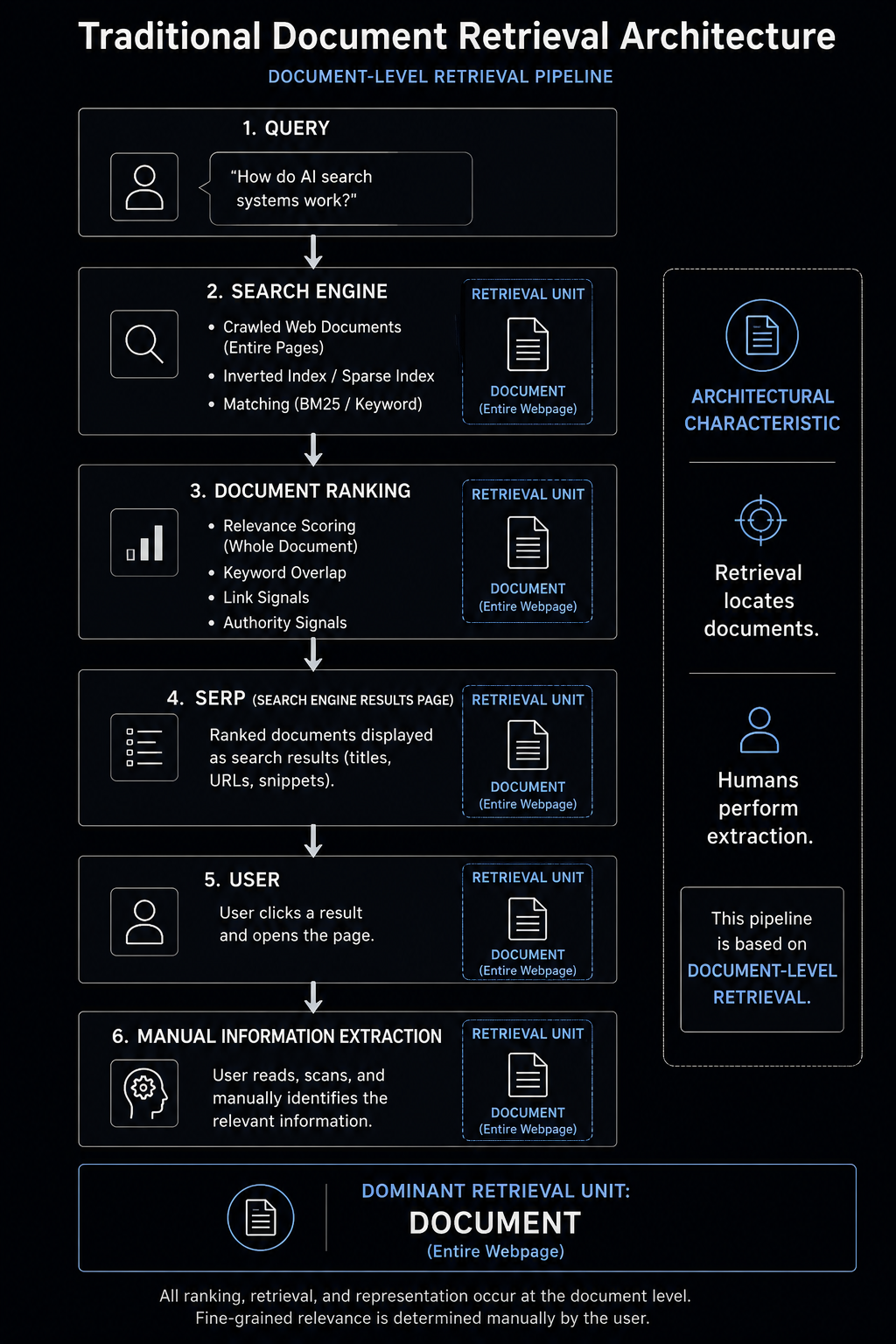
As long as search primarily functioned as a navigational system for humans, this dependency remained stable.
The transition begins once retrieval systems no longer retrieve documents primarily for navigation, but increasingly retrieve information for downstream synthesis systems.
Section 1 Summary
Traditional search systems treated entire webpages as Document Retrieval Units because retrieval infrastructure was designed for Document Retrieval rather than extracting specific Evidence. Users performed information extraction manually after retrieval, allowing document-level competition to remain operationally effective. This document-centric retrieval architecture established the foundation upon which later retrieval systems evolved.
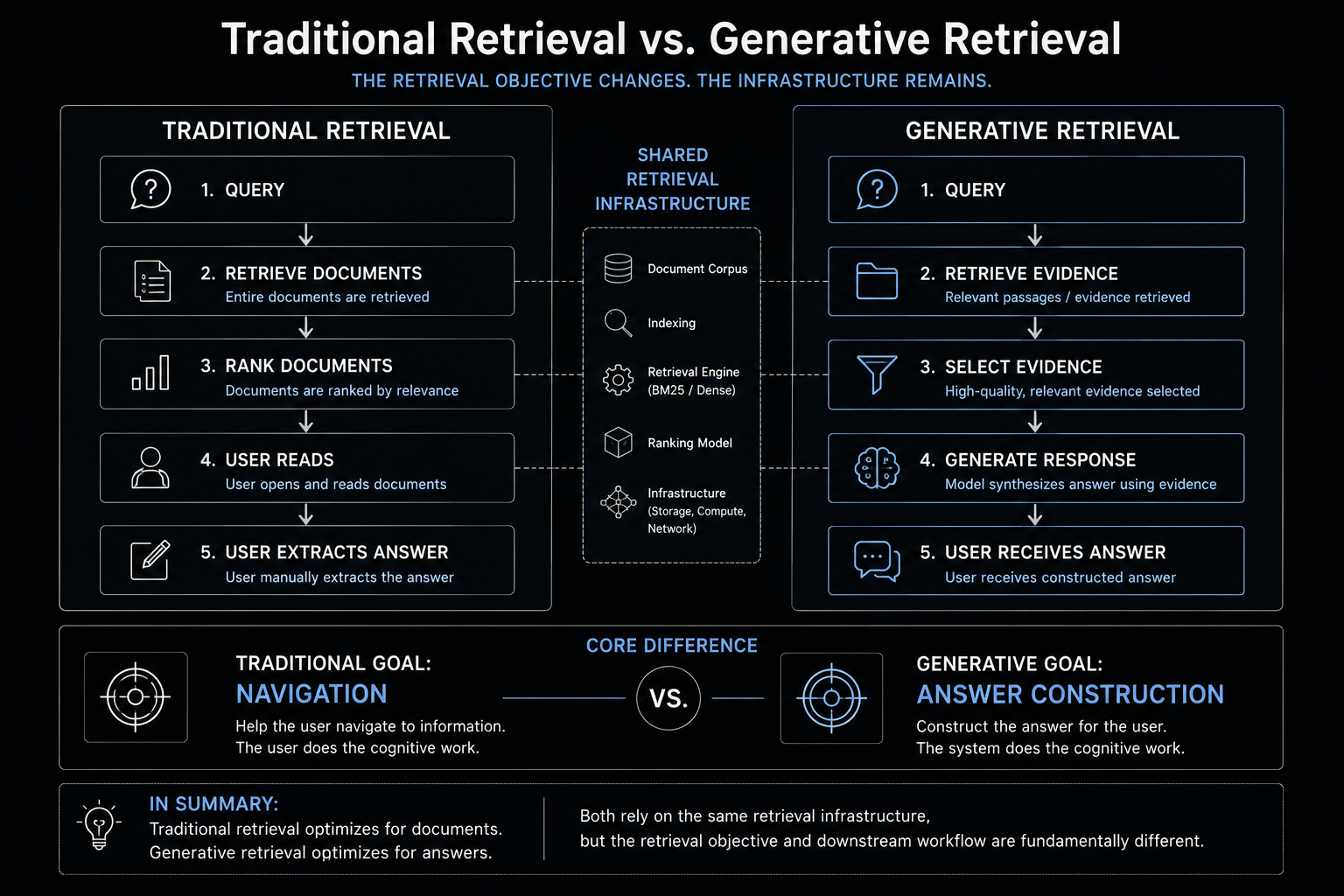
How Did Generative AI Systems Change The Retrieval Objective?
Generative AI systems changed the retrieval objective by shifting retrieval optimization from Document Retrieval Visibility toward synthesis-oriented Evidence Selection. Traditional search systems evaluated success primarily by determining whether a relevant document had been retrieved, while retrieval-augmented generation (RAG) systems increasingly evaluate success by whether retrieved Evidence can support grounded synthesis inside constrained generation pipelines. This distinction is operationally significant because a document may be broadly relevant to a query while still functioning as a poor synthesis input due to mixed topics, navigation structures, boilerplate content, and low Evidence Density semantic regions. As retrieval becomes upstream infrastructure for generative systems, retrieval quality becomes increasingly tied to Evidence Density, extractability, contextual relevance, and grounding utility rather than document relevance alone. The architectural consequence is a growing preference for localized Passage Retrieval Units capable of delivering higher Evidence Density inside retrieval and generation workflows.
Traditional search systems optimized primarily for Document Retrieval Visibility rather than Evidence Extraction. Traditional search systems separated retrieval from extraction. Retrieval systems located relevant documents, while humans identified relevant sections and extracted the information necessary to answer their questions.
Retrieval-augmented generation systems destabilize this architecture because retrieval no longer terminates at document discovery.
Modern retrieval systems increasingly operate as upstream infrastructure for synthesis systems. Rather than retrieving documents primarily for navigation, retrieval pipelines now supply language models with Evidence capable of supporting grounded response generation.
This changes how retrieval quality is evaluated.
Traditional search systems could largely measure retrieval success at the document level:
Did the system retrieve a relevant page?
Generative systems introduce a narrower operational requirement:
Did the system retrieve Evidence that can actually be used inside synthesis pipelines?
This distinction fundamentally changes retrieval incentives.
A document may be broadly relevant to a query while still functioning as a poor synthesis input. Large webpages frequently contain:
-
multiple topical regions
-
navigation structures
-
repeated boilerplate
-
mixed informational intent
-
low Evidence Density semantic regions
-
structurally irrelevant content
Human readers can selectively filter this efficiently while navigating documents. Generation systems inherit that filtering burden directly.
Retrieved information now competes for limited context allocation alongside:
-
system prompts
-
conversation history
-
user queries
-
generated output
As retrieval moves closer to generation, retrieval constraints become increasingly tied to:
-
Evidence Density
-
contextual relevance
-
extractability
-
grounding utility
-
context efficiency
The retrieval objective therefore begins shifting away from:
retrieving potentially useful Document Retrieval Units
toward:
retrieving operationally usable Evidence contained within Passage Retrieval Units.
This transition creates pressure toward smaller Passage Retrieval Units.
Modern retrieval systems increasingly isolate:
-
Passage Retrieval Units
-
Evidence Spans
-
localized Evidence
rather than relying exclusively on full-document retrieval.
The shift is not merely architectural preference.
It emerges from synthesis constraints themselves.
Retrieval systems feeding generative models must maximize useful information per retrieved token. Entire documents frequently introduce excessive contextual overhead relative to the amount of directly usable Evidence they contain. A single highly relevant paragraph answering a query may exist inside a multi-thousand-word page whose remaining content contributes little value to synthesis quality.
Traditional retrieval optimized for Document Retrieval Visibility, whereas generative retrieval increasingly optimizes for Evidence usability inside synthesis systems.
Generative retrieval pipelines increasingly optimize:
-
Evidence Selection
-
grounding quality
-
retrieval precision
-
context-efficient synthesis
As retrieval systems increasingly operate on smaller Passage Retrieval Units rather than complete Document Retrieval Units, Document Retrieval begins becoming operationally insufficient. Highly relevant information becomes increasingly difficult to isolate once entire pages are treated as single Document Retrieval Units containing many competing semantic signals.
The transition from Document Retrieval to Passage Retrieval therefore begins with a deeper architectural shift:
retrieval is no longer optimized primarily for navigation.
It is increasingly optimized for synthesis.
Section 2 Summary
Generative retrieval systems changed the retrieval objective from Document Retrieval toward supplying synthesis-ready Evidence. As retrieval becomes upstream infrastructure for generation systems, retrieval quality increasingly depends on Evidence Density, extractability, contextual relevance, and grounding utility rather than document relevance alone. This architectural shift creates growing pressure toward Passage Retrieval Units capable of supporting efficient Evidence Selection.
Why Does Whole-Page Retrieval Cause Semantic Dilution In Dense Retrieval Systems?
Whole-page retrieval creates Semantic Dilution because dense retrieval systems compress entire Document Retrieval Units into single vector embeddings, forcing multiple Semantic Regions to share the same representational space. Semantic Dilution occurs when localized concepts lose retrieval distinctiveness because their semantic signals become averaged together inside a broader document-level embedding. In dense retrieval architectures, queries and Document Retrieval Units compete through geometric similarity in vector space, making representational precision critical for accurate retrieval. When pricing information, technical definitions, troubleshooting instructions, and navigational content are aggregated into one embedding, highly relevant Evidence becomes less separable from surrounding thematic content. Retrieval precision degrades because localized Evidence can no longer maintain equally strong alignment with query vectors across all concepts contained within the document. Passage Retrieval emerged as the architectural response to this problem by independently embedding smaller Passage Retrieval Units that preserve sharper semantic boundaries, stronger query alignment, and greater retrieval specificity.
Dense retrieval systems introduce a new retrieval challenge: semantically distinct information contained within the same Document Retrieval Unit is compressed into a shared vector representation.
As retrieval systems increasingly optimize for synthesis utility rather than document navigation, this representational compression makes localized Evidence harder to retrieve accurately. The result is Semantic Dilution, where relevant Evidence loses Retrieval Visibility inside broader document-level meaning.
Traditional lexical retrieval systems such as BM25 evaluated documents through sparse keyword matching. Under this architecture, even a large document could remain retrievable if relevant lexical signals existed somewhere inside the page. Dense retrieval changes retrieval behavior fundamentally because retrieval no longer operates primarily through sparse term overlap.
Dense retrieval systems implement this architecture by encoding Document Retrieval Units into high-dimensional vector representations. Queries and indexed Document Retrieval Units are embedded into a shared semantic space, allowing retrieval systems to identify semantically related content through geometric proximity rather than exact lexical matching.
This introduces a new infrastructure problem:
Semantic Dilution.
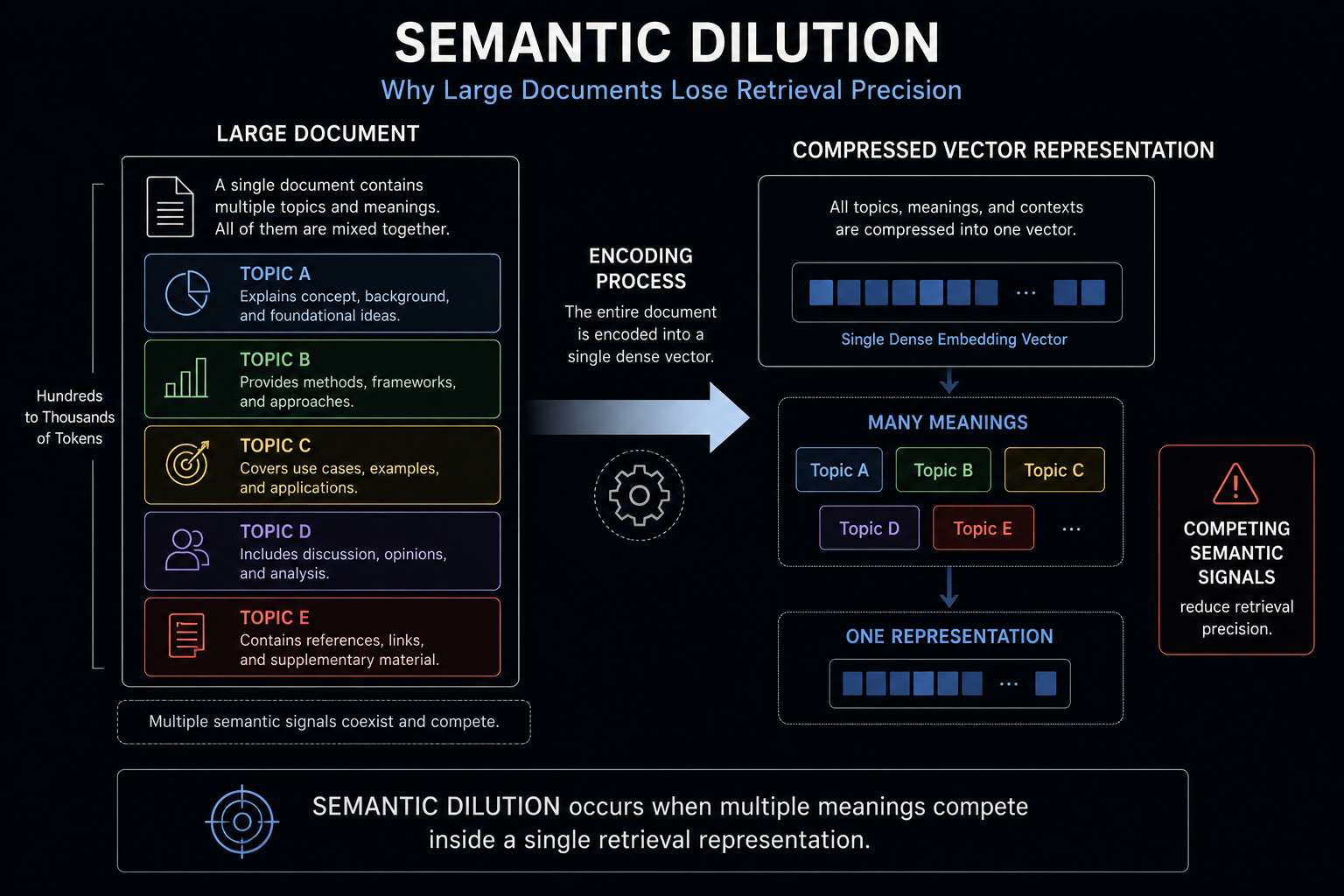
Large Document Retrieval Units commonly contain:
-
multiple Semantic Regions
-
heterogeneous topical zones
-
mixed informational intent
-
unrelated supporting context
-
competing informational signals
When an embedding model compresses an entire Document Retrieval Unit into a single vector representation, these distinct Semantic Regions become aggregated into one representation.
The resulting embedding behaves as a semantic average of the Document Retrieval Unit.
Highly relevant Evidence Spans therefore lose representational distinctiveness because their semantic signals become diluted by surrounding thematic context. A highly relevant pricing paragraph, technical definition, or troubleshooting instruction must now compete against the semantic mass of the remaining document occupying the same embedding space.
This is not merely a content-noise problem.
It is a representation compression failure inside embedding space itself.
Dense retrieval systems depend on geometric separability between query vectors and retrieval vectors. When many unrelated semantic signals are compressed into one embedding, the vector cannot preserve equally strong alignment for every localized concept contained within the Document Retrieval Unit.
Retrieval precision begins degrading because localized Evidence loses semantic separability.
A query about pricing may align strongly with a pricing passage embedding, but not with a homepage embedding containing pricing alongside dozens of unrelated Semantic Regions.
Retrieval Granularity therefore becomes an architectural constraint. As Document Retrieval Units become larger, semantic competition inside embeddings intensifies. Multiple Semantic Regions compete for representational dominance within the same vector space. The broader the semantic scope of the Document Retrieval Unit, the weaker its ability to preserve precise query-aligned signals.
This creates a Retrieval Visibility problem for localized Evidence.
Highly relevant Evidence Spans become increasingly difficult to isolate once they are compressed into broad document-level representations.
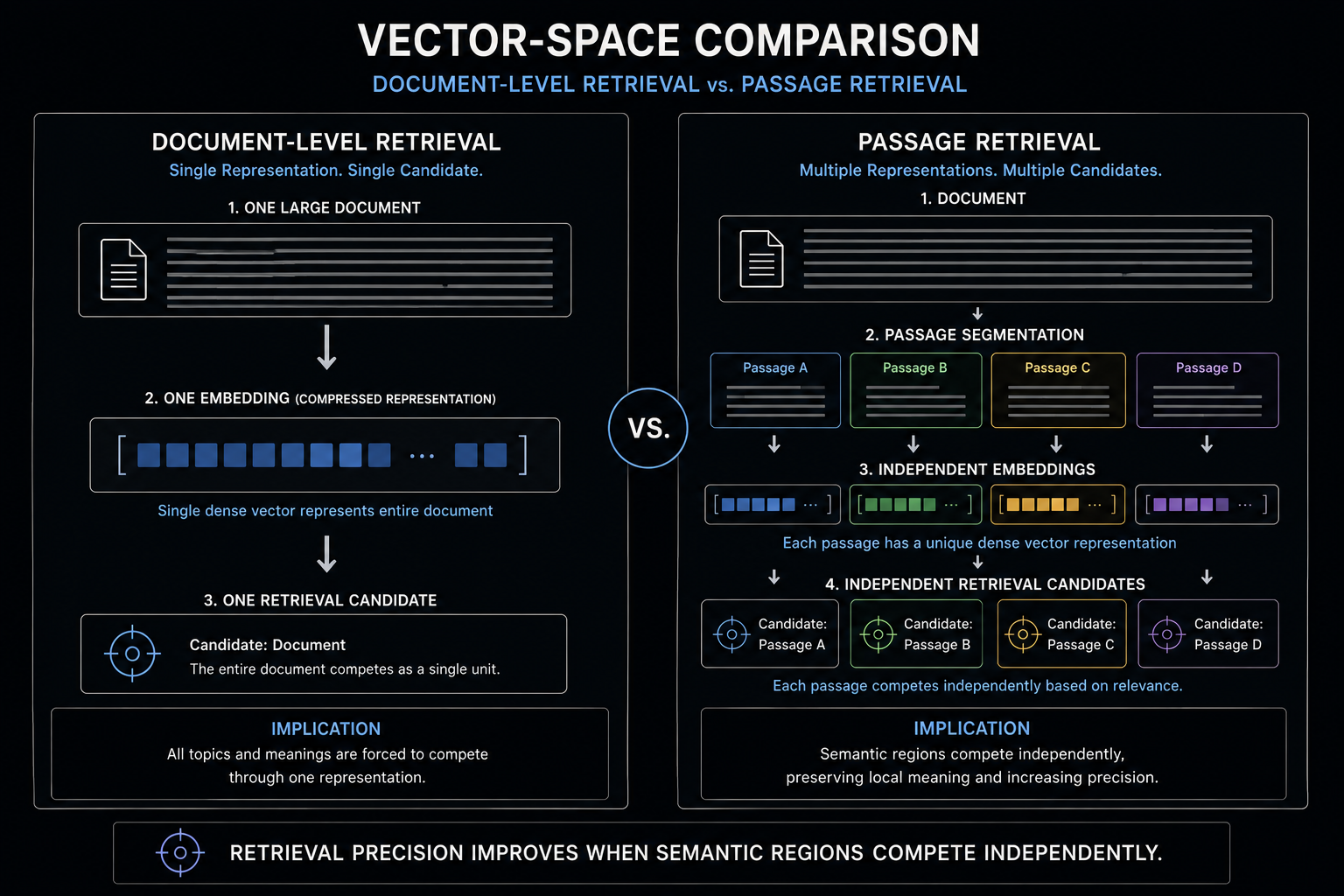
The architectural response to this problem was Passage Retrieval.
Dense Passage Retrieval (DPR) later operationalized this architectural transition.
DPR operationalized a different retrieval assumption:
the optimal Retrieval Unit for dense retrieval systems may not be the Document Retrieval Unit,
but the Passage Retrieval Unit.
Rather than embedding entire webpages as single Document Retrieval Units, DPR independently indexes Passage Retrieval Units. Queries and passages are encoded separately through a dual-encoder architecture, allowing retrieval systems to compute semantic similarity directly between query vectors and localized passage embeddings.
This changes retrieval dynamics fundamentally.
Smaller Passage Retrieval Units preserve tighter semantic boundaries and reduce representational interference. Individual Passage Retrieval Units compete independently inside retrieval space rather than being submerged within broader Document Retrieval Unit embeddings.
A troubleshooting passage competes independently from surrounding marketing copy.
A technical definition competes independently from navigational context.
A pricing explanation competes independently from unrelated product descriptions.
Localized Evidence regains semantic separability.
DPR demonstrated that passage-level dense retrieval substantially outperformed strong BM25 baselines across open-domain question-answering benchmarks, improving retrieval accuracy across multiple datasets.
Its significance was infrastructural.
Passage Retrieval emerged as the architectural response to Semantic Dilution because smaller Passage Retrieval Units preserve stronger semantic boundaries and higher Evidence Density inside dense retrieval systems. DPR validated this architectural direction by demonstrating that independently retrieved passages produced substantially higher retrieval accuracy than whole-document retrieval across open-domain question-answering benchmarks.
This architectural transition was subsequently validated and institutionalized through passage-level retrieval benchmarks such as MS MARCO, where retrieval systems increasingly optimized around Passage Retrieval Units rather than entire webpages.
The field progressively shifted from:
competition between Document Retrieval Units
toward:
competition between Passage Retrieval Units.
Retrieval systems increasingly optimized for localized semantic precision rather than broad document approximation.
Passage Retrieval therefore emerged as the structural response to Semantic Dilution itself.
Whole-page embeddings compress too many competing semantic signals into one Document Retrieval Unit. Smaller Passage Retrieval Units preserve stronger semantic boundaries, sharper query alignment, and higher retrieval precision.
But semantic precision alone does not fully stabilize retrieval systems.
Even semantically precise retrieval remains operationally constrained once retrieved Evidence must compete inside finite generation contexts with limited token budgets and attention allocation.
Section 3 Summary
Semantic Dilution emerges when multiple Semantic Regions are compressed into a shared retrieval representation, reducing Retrieval Visibility for localized Evidence. Dense retrieval systems amplify this problem because retrieval depends on semantic separability within embedding space. Passage Retrieval emerged as the architectural response by allowing smaller Passage Retrieval Units to preserve stronger semantic boundaries and sharper query alignment.
How Do Context Window Constraints Make Whole-Page Retrieval Operationally Inefficient?
Context Compression makes whole-page retrieval operationally inefficient because modern retrieval pipelines must fit useful Evidence into finite context windows governed by token budgets and limited attention allocation capacity. Context Compression pressure emerges when retrieved information competes for scarce synthesis-visible space, forcing retrieval systems to maximize useful Evidence per context token rather than simply maximize relevance. Under these constraints, entire documents often introduce large quantities of low-value contextual material that consume attention without proportionally improving retrieval utility. Research on long-context transformer behavior, including the Lost in the Middle findings, demonstrated that information embedded within lengthy contexts becomes increasingly difficult for models to utilize consistently, even when the information remains technically present. As context length expands, attention dilution and distractor interference reduce the operational visibility of high-value Evidence by forcing it to compete against surrounding contextual mass. Passage Retrieval therefore becomes operationally advantageous because smaller Passage Retrieval Units preserve higher Evidence Density, consume fewer context resources, and survive Context Compression constraints more effectively than whole-document Document Retrieval Units.
Context Compression introduces a second limitation on whole-page retrieval. Even when dense retrieval systems successfully identify relevant information, retrieved Evidence must still compete for limited space within context windows, token budgets, and attention allocation systems.
Modern retrieval pipelines operate under finite:
-
context windows
-
token budgets
-
attention allocation capacity
-
synthesis bandwidth
Retrieved information therefore competes for limited representational space inside generation pipelines. The context window is not merely a storage container for retrieved text. It is a constrained allocation environment where every retrieved token displaces alternative information that could occupy the same synthesis capacity.
This creates retrieval compression pressure.
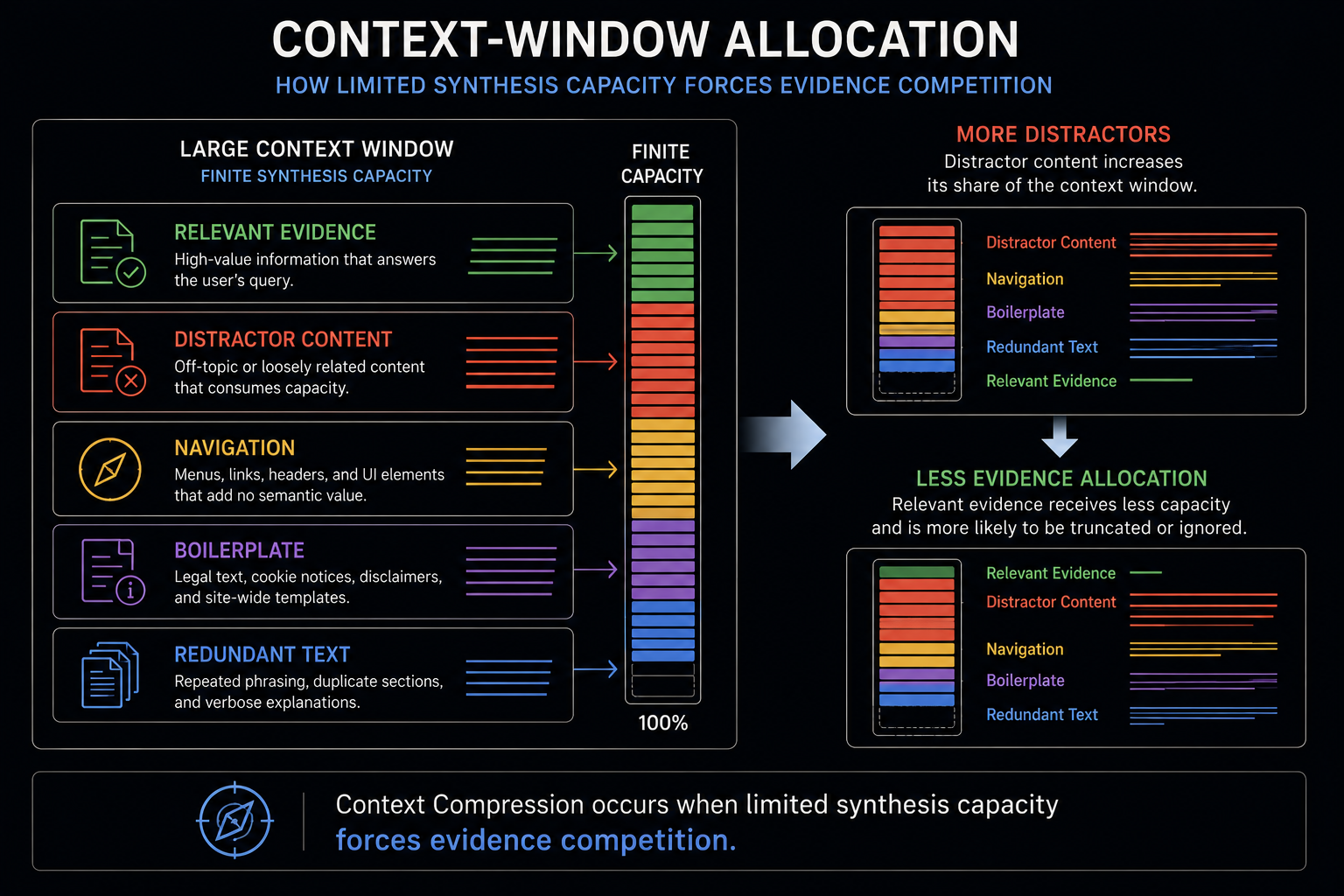
Retrieval systems are no longer selecting only what is relevant.
They are increasingly selecting what deserves limited synthesis capacity.
The operational problem therefore shifts from:
“Can the system retrieve relevant information?”
toward:
“Can highly useful Evidence survive efficiently inside constrained generation contexts?”
Traditional search systems did not operate under this constraint structure because retrieval terminated at navigation. Once a relevant page was surfaced, users absorbed the burden of filtering irrelevant material manually.
Generation systems inherit that burden directly.
Every irrelevant paragraph, navigational block, repeated disclaimer, or low Evidence Density Semantic Region inserted into context consumes:
-
token budget
-
attention capacity
-
inference cost
-
synthesis opportunity
-
without proportionally improving grounding quality.
Whole-document retrieval therefore becomes operationally inefficient even when the retrieved page is broadly relevant.
A multi-thousand-word webpage may contain only a few highly useful Evidence Spans surrounded by large quantities of operationally irrelevant text. Under constrained generation environments, these irrelevant regions become distractor tokens competing against higher-value Evidence for finite model attention.
This is fundamentally a context-economics problem.
The issue is not simply whether relevant information exists somewhere inside the retrieved document.
The issue is whether useful Evidence remains operationally visible once inserted into constrained attention systems.
This instability becomes more severe as context length increases.
Research on long-context transformer behavior exposed this directly. The Stanford and UC Berkeley paper Lost in the Middle demonstrated that model performance follows a U-shaped retrieval curve: information near the beginning and end of long contexts remains relatively accessible, while information embedded in the middle becomes significantly harder for models to utilize effectively.
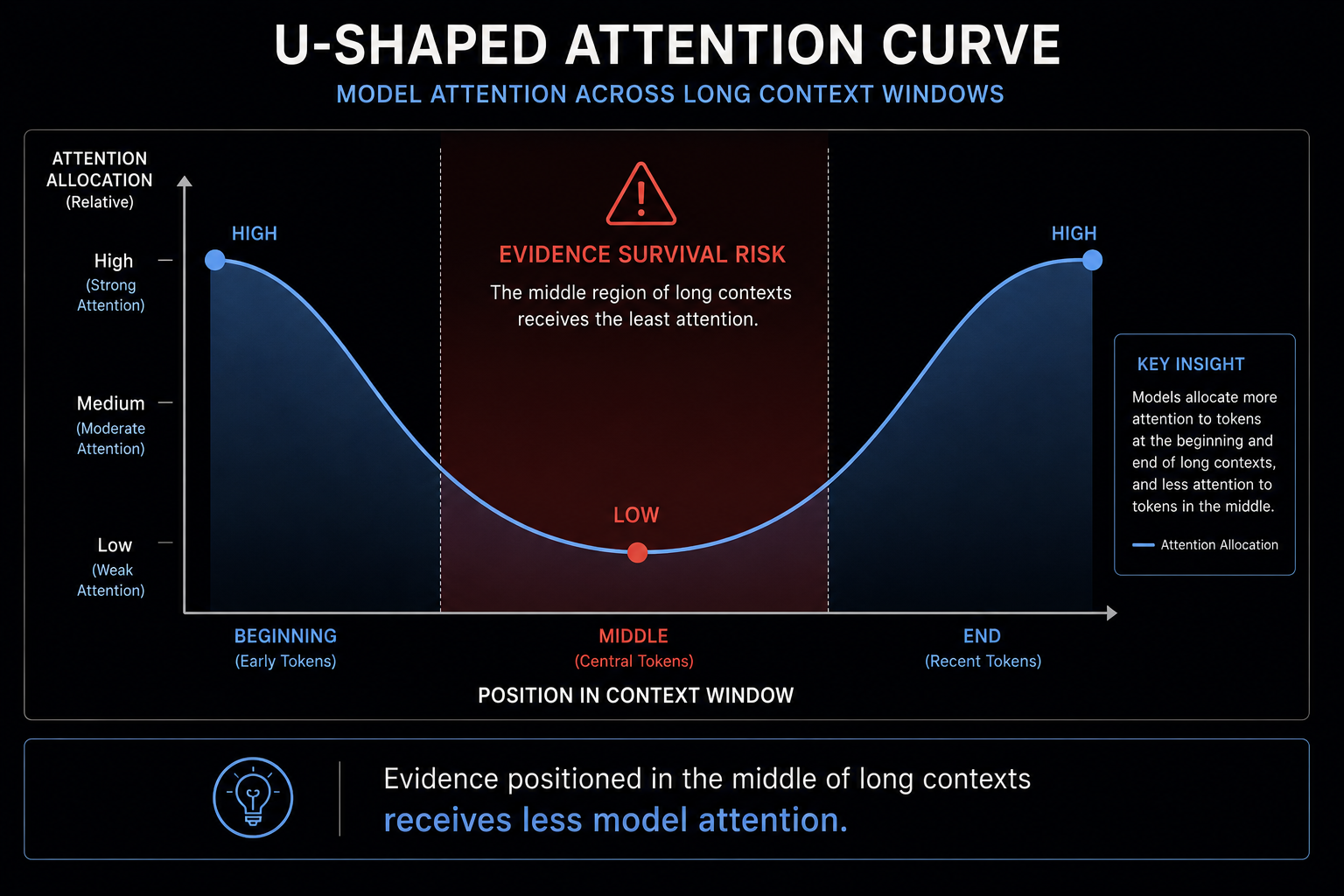
This degradation persists even in long-context frontier models.
The critical failure is not simply context-window size.
It is attention allocation efficiency.
Larger context windows increase how much information fits into the model, but they do not guarantee that highly relevant Evidence retains sufficient visibility once surrounded by thousands of competing tokens. As context length expands, attention weights become increasingly diluted across irrelevant or weakly relevant information.
Two operational failures emerge:
-
attention dilution
-
distractor interference
Attention dilution occurs when relevant Evidence competes against excessive contextual mass, weakening the model’s ability to consistently prioritize high-value Evidence Spans.
Distractor interference occurs when irrelevant or tangential content introduces competing semantic signals that reduce synthesis precision or distort grounding behavior.
Retrieval quality therefore becomes increasingly tied to:
-
Evidence Density
-
context efficiency
-
synthesis visibility
-
compression efficiency
The operational objective becomes:
maximize useful Evidence per context token.
This changes the retrieval value of documents themselves.
Large documents often behave as low-density Evidence containers. Even when semantically relevant overall, they distribute useful information unevenly across long textual regions. Entire pages therefore consume disproportionately large amounts of synthesis capacity relative to the amount of grounding-quality Evidence they contribute.
Passage Retrieval emerges as the operational response to this imbalance.
Smaller Passage Retrieval Units improve:
-
Evidence Density
-
context efficiency
-
synthesis precision
-
attention survivability
A highly relevant paragraph inserted into context introduces far less distractor mass than an entire webpage containing surrounding navigational structures, redundant explanations, unrelated sections, and semantically competing material.
Passage-level retrieval therefore functions as a form of retrieval compression.
Broad documents are compressed into smaller Evidence units capable of surviving constrained synthesis environments more efficiently.
This is why Passage Retrieval cannot be explained solely through embedding mechanics or vector-search precision.
The deeper architectural driver is operational context economics.
Retrieval systems increasingly optimize around finite evidence-allocation capacity inside generation pipelines.
Smaller Passage Retrieval Units survive these constraints more effectively because they preserve:
-
higher Evidence Density
-
stronger attention visibility
-
lower distractor interference
-
greater synthesis efficiency
Once retrieval systems become dependent on smaller Evidence units operationally, document-level retrieval objects become increasingly impractical as direct indexing units.
Retrieval pipelines increasingly require documents to be segmented into independently retrievable components capable of competing separately inside both retrieval and synthesis environments.
Section 4 Summary
Context Compression exposes the operational limits of whole-page retrieval within finite synthesis environments. Retrieved information must compete for limited context allocation, attention capacity, and Evidence survivability. Passage Retrieval improves context efficiency by maximizing useful Evidence per retrieved token while reducing distractor interference and attention dilution.
How Does Passage Retrieval Architecture Differ From Document Retrieval?
Passage Retrieval differs from Document Retrieval by indexing and retrieving localized Semantic Regions independently rather than treating entire documents as single Document Retrieval Units. Under Document Retrieval, all content within a webpage competes through one retrieval representation, whereas Passage Retrieval allows individual Evidence Spans to compete separately within retrieval systems. Dense Passage Retrieval (DPR), introduced by Karpukhin et al., operationalized this architecture through a dual-encoder design in which queries and passages are encoded independently into dense vector embeddings and matched through similarity search. Independent passage indexing allows highly relevant Evidence to surface even when it exists inside documents that are otherwise weak retrieval candidates, fundamentally shifting retrieval competition from document competition toward evidence competition. This architectural transition improves semantic precision because localized information no longer competes against unrelated content embedded within the same Document Retrieval Unit. As passage-level indexing expands retrieval scale from document collections to billions of independently searchable Semantic Regions, scalable retrieval infrastructure such as Approximate Nearest Neighbor (ANN) search becomes necessary to maintain practical retrieval latency.
Semantic Dilution and Context Compression exposed fundamental limitations in document-level retrieval architectures. Retrieval systems increasingly required Retrieval Units that could compete independently, preserve localized relevance, and operate efficiently within constrained retrieval and synthesis environments.
Passage Retrieval emerged as the architectural response to these constraints. Instead of treating entire documents as retrieval candidates, modern retrieval systems began indexing and ranking smaller Passage Retrieval Units capable of competing directly for Retrieval Visibility.
Once retrieval systems optimize around:
-
localized semantic precision
-
higher Evidence Density
-
synthesis efficiency
-
context survivability
-
document-level retrieval architectures begin breaking down structurally.
-
Retrieval systems therefore reorganize around a different operational Retrieval Unit:
-
the passage.
This transition fundamentally changes retrieval architecture itself.
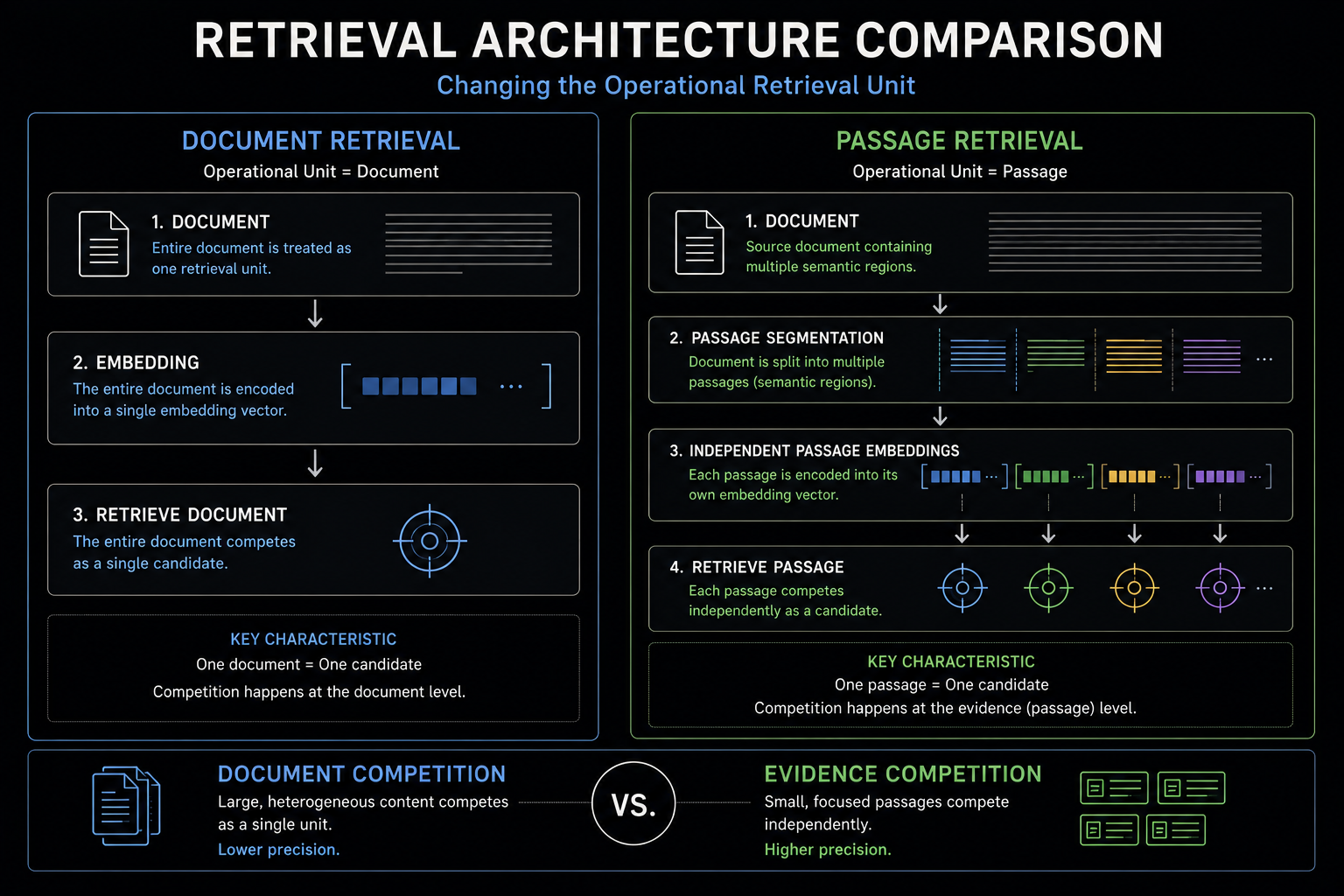
Traditional search systems indexed documents as globally competing retrieval entities. Passage Retrieval architectures instead index smaller Semantic Regions independently, allowing localized Evidence to participate separately inside retrieval pipelines.
This is fundamentally a Retrieval Granularity transformation.
Retrieval Granularity determines the size of the unit that:
-
receives an embedding
-
enters the retrieval index
-
participates in similarity search
-
competes during candidate selection
-
survives into synthesis environments
Changing the Retrieval Unit changes the operational behavior of the entire retrieval system.
Under document-level retrieval, large heterogeneous webpages compete as single semantic objects.
Under Passage Retrieval, localized Semantic Regions compete independently.
A troubleshooting instruction no longer competes alongside unrelated product explanations.
A pricing paragraph no longer competes as part of an entire homepage.
A technical definition no longer competes against surrounding navigational structures and contextual noise.
Each Semantic Region becomes independently retrievable.
Multiple implementation approaches can support passage retrieval architectures. Dense Passage Retrieval (DPR) emerged as one influential implementation of this architectural direction.
This architectural transition emerged directly through Dense Passage Retrieval (DPR). Karpukhin et al. operationalized the idea that retrieval systems could independently encode and retrieve passage-level units rather than entire documents.
Mechanically, DPR uses a dual-encoder retrieval architecture.
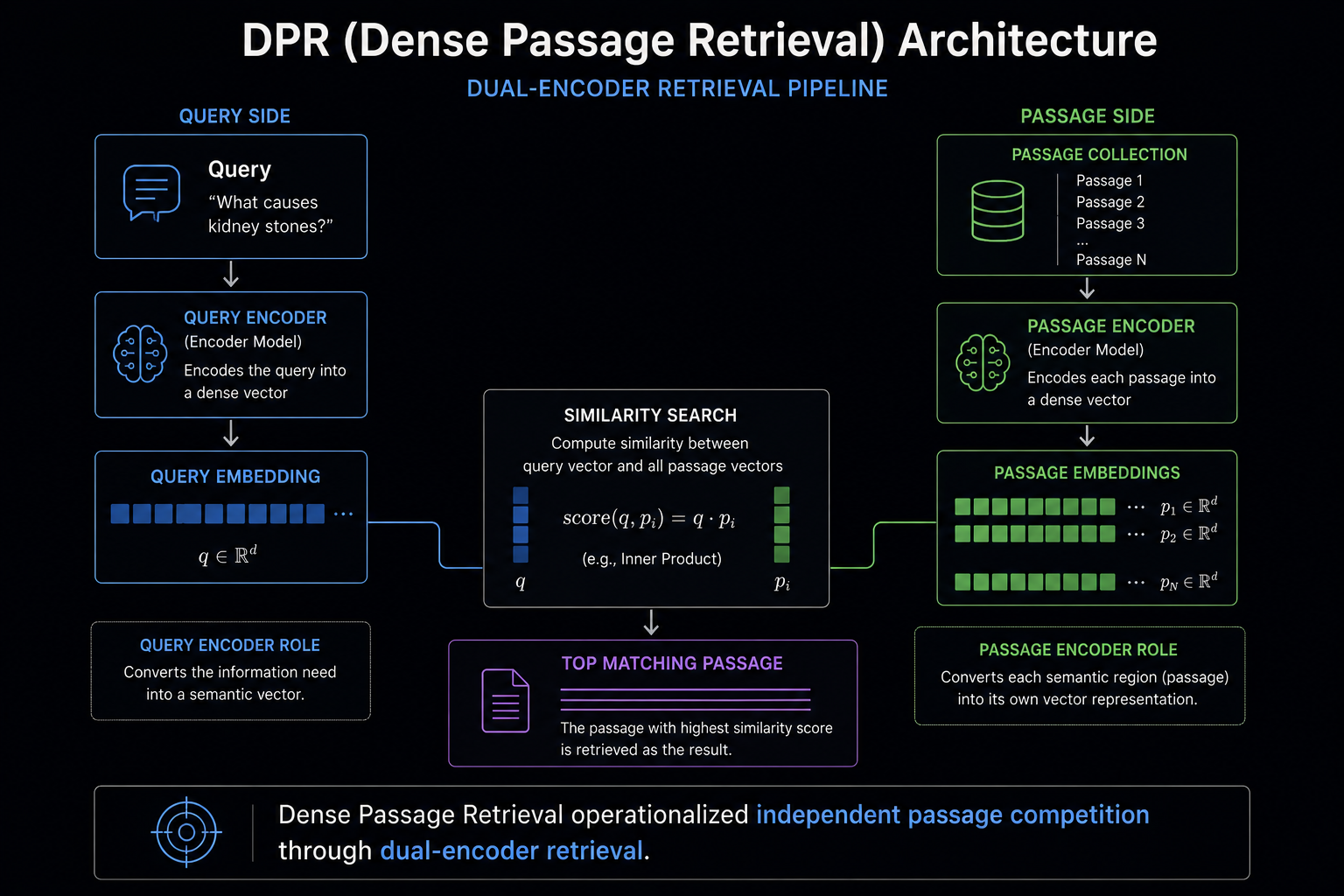
Queries and passages are encoded independently into dense vector representations. Retrieval systems then compute similarity between query embeddings and indexed passage embeddings through nearest-neighbor search inside vector space.
The architectural significance extends beyond encoder design itself.
DPR provided empirical support for a different retrieval assumption:
retrieval systems perform more effectively when Semantic Regions compete independently rather than being compressed into monolithic document representations.
Passage-level retrieval improves:
-
retrieval precision
-
retrieval recall
-
semantic separability
-
synthesis compatibility
-
evidence allocation efficiency
because smaller Passage Retrieval Units preserve tighter semantic boundaries and sharper query alignment.
This transition also changes retrieval competition itself.
Traditional search systems optimized global document competition.
Passage Retrieval architectures create localized evidence competition.
Highly relevant Evidence Spans embedded deep inside weak documents can still surface successfully if their local semantic alignment strongly matches the query. Conversely, high-authority documents containing weakly relevant local Evidence may fail retrieval despite broad topical similarity.
Retrieval systems therefore increasingly optimize around:
- evidence competition
rather than:
- document competition.
Operationally, this transformation requires passage-level indexing infrastructure.
Instead of storing one embedding per document, modern retrieval systems increasingly generate embeddings for:
-
passages
-
Evidence Spans
-
paragraph-level segments
-
independently retrievable Passage Retrieval Units
Each indexed segment becomes independently searchable inside vector retrieval systems.
This dramatically expands retrieval scale.
Traditional search systems retrieved among millions or billions of webpages.
Passage Retrieval systems increasingly retrieve among billions of independently indexed Semantic Regions.
The infrastructure challenge therefore changes fundamentally.
The problem is no longer simply:
“How do we rank webpages efficiently?”
It increasingly becomes:
“How do we search enormous vector spaces containing billions of independently retrievable passage embeddings fast enough for real-time retrieval pipelines?”
The architectural consequence of independently indexing large numbers of Passage Retrieval Units is a dramatic expansion in retrieval search space. This creates an infrastructure requirement for scalable similarity search before any specific retrieval algorithm can be applied.
This scaling transition drives the rise of Approximate Nearest Neighbor (ANN) retrieval systems.
Once retrieval systems begin indexing billions of independently retrievable passages, exhaustive similarity search becomes operationally impractical. Retrieval architectures therefore increasingly rely on ANN retrieval methods that prioritize retrieval speed while preserving sufficiently strong recall.
The architectural significance of ANN retrieval is not the underlying indexing technique itself.
Its significance is that Passage Retrieval dramatically expands the number of retrieval candidates competing inside the system. Efficient approximate retrieval becomes necessary to identify relevant Evidence quickly enough for real-time retrieval pipelines.
ANN retrieval therefore emerges as an enabling infrastructure for passage-level retrieval.
Without scalable candidate retrieval, independently indexed passage architectures become difficult to operate at production scale.
This also changes how retrieval recall is optimized.
First-stage retrieval increasingly operates as a broad candidate-generation system designed to maximize the probability that highly relevant Evidence survives early retrieval competition.
Instead of retrieving a single “best document,” Passage Retrieval systems retrieve top-k candidate passages capable of competing downstream for synthesis allocation.
Retrieval therefore becomes increasingly:
-
probabilistic
-
competitive
-
recall-oriented
-
candidate-centric
The retrieval objective shifts toward maximizing Evidence survivability under constrained retrieval latency and synthesis capacity.
Passage Retrieval architectures therefore begin functioning less like navigational search systems and more like evidence-selection infrastructures feeding downstream generation pipelines.
Retrieval systems no longer optimize primarily around routing users toward webpages.
They increasingly optimize around:
-
localized Evidence isolation
-
retrieval compression
-
synthesis-compatible Passage Retrieval Units
-
scalable candidate competition
The dominant operational retrieval object increasingly becomes:
the passage.
But this creates another infrastructure dependency.
Once retrieval systems depend on independently retrievable Semantic Regions, documents can no longer remain structurally monolithic during indexing.
Retrieval systems must now determine:
-
where retrieval boundaries should exist
-
how documents should be segmented
-
how semantic continuity survives decomposition
-
how retrieval units preserve contextual coherence after separation
Passage Retrieval therefore creates the next infrastructure requirement:
documents must be operationally segmented into stable retrievable boundaries before indexing can occur.
Section 5 Summary
Passage Retrieval transforms retrieval architecture by replacing document-level competition with independent competition between Passage Retrieval Units. DPR demonstrated that localized Semantic Regions can be indexed, embedded, and retrieved independently, improving retrieval precision and synthesis compatibility. As retrieval systems scale toward billions of independently searchable Semantic Regions, infrastructure such as ANN retrieval becomes essential for maintaining retrieval efficiency.
Key Takeaways:
• Modern AI retrieval systems increasingly optimize for Evidence Selection rather than Document Retrieval Visibility.
• Semantic Dilution occurs when multiple Semantic Regions are compressed into a single retrieval representation, reducing Retrieval Visibility for localized Evidence.
• Context Compression emerges when finite synthesis capacity forces retrieved information to compete for limited attention allocation and context resources.
• Passage Retrieval improves retrieval precision by allowing localized Semantic Regions and Evidence Spans to compete independently.
• Dense Passage Retrieval (DPR) operationalized passage-level competition through independent query and passage embeddings.
• Modern retrieval systems increasingly function as evidence-selection infrastructures rather than navigational document-discovery systems.
• The dominant operational Retrieval Unit increasingly becomes the Passage Retrieval Unit rather than the Document Retrieval Unit.
Conclusion : The Shift to Passage Retrieval
The progression of modern retrieval systems reflects a series of architectural responses to changing computational constraints rather than a sequence of isolated algorithmic improvements. Traditional search infrastructure treated documents as the natural unit of retrieval because its objective was navigational. Retrieval systems located relevant pages, while human readers performed the remaining work of identifying useful information within those documents. As long as retrieval ended at navigation, document-level retrieval remained both operationally efficient and computationally practical.
The emergence of generative AI fundamentally changed this objective. Retrieval no longer existed simply to direct users toward potentially relevant documents. Instead, it became the upstream Evidence Selection layer supporting synthesis systems that generate answers directly from retrieved information. This shift exposed limitations that document-centric retrieval had previously been able to tolerate. Entire webpages frequently combine multiple topics, navigational elements, contextual explanations, and Semantic Regions with varying relevance. While humans can effortlessly ignore these distractions, generation systems must process whatever retrieval provides.
These new operational demands revealed two increasingly significant architectural pressures. First, dense retrieval systems struggle to preserve the distinctiveness of localized Evidence when entire documents are represented as single Document Retrieval Units, producing Semantic Dilution that weakens retrieval precision. Second, finite context windows force retrieval pipelines to compete for limited synthesis capacity, making large documents inefficient carriers of Evidence even when they are broadly relevant. Together, these constraints altered the economics of retrieval itself. The system could no longer optimize around finding relevant documents alone. It increasingly needed to retrieve Evidence that could survive both retrieval and synthesis under constrained computational resources.
Passage Retrieval emerged as the logical consequence of these pressures. Rather than representing a simple optimization or implementation preference, it reflects a structural change in how modern retrieval systems define the object of retrieval. By allowing localized Evidence to compete independently, Passage Retrieval preserves semantic specificity, improves Evidence Density, and aligns retrieval outputs with the operational requirements of downstream generation systems. The transition from Document Retrieval to Passage Retrieval therefore represents a change in retrieval architecture itself, not merely a refinement of existing ranking techniques.
This progression establishes the central conclusion of the article.
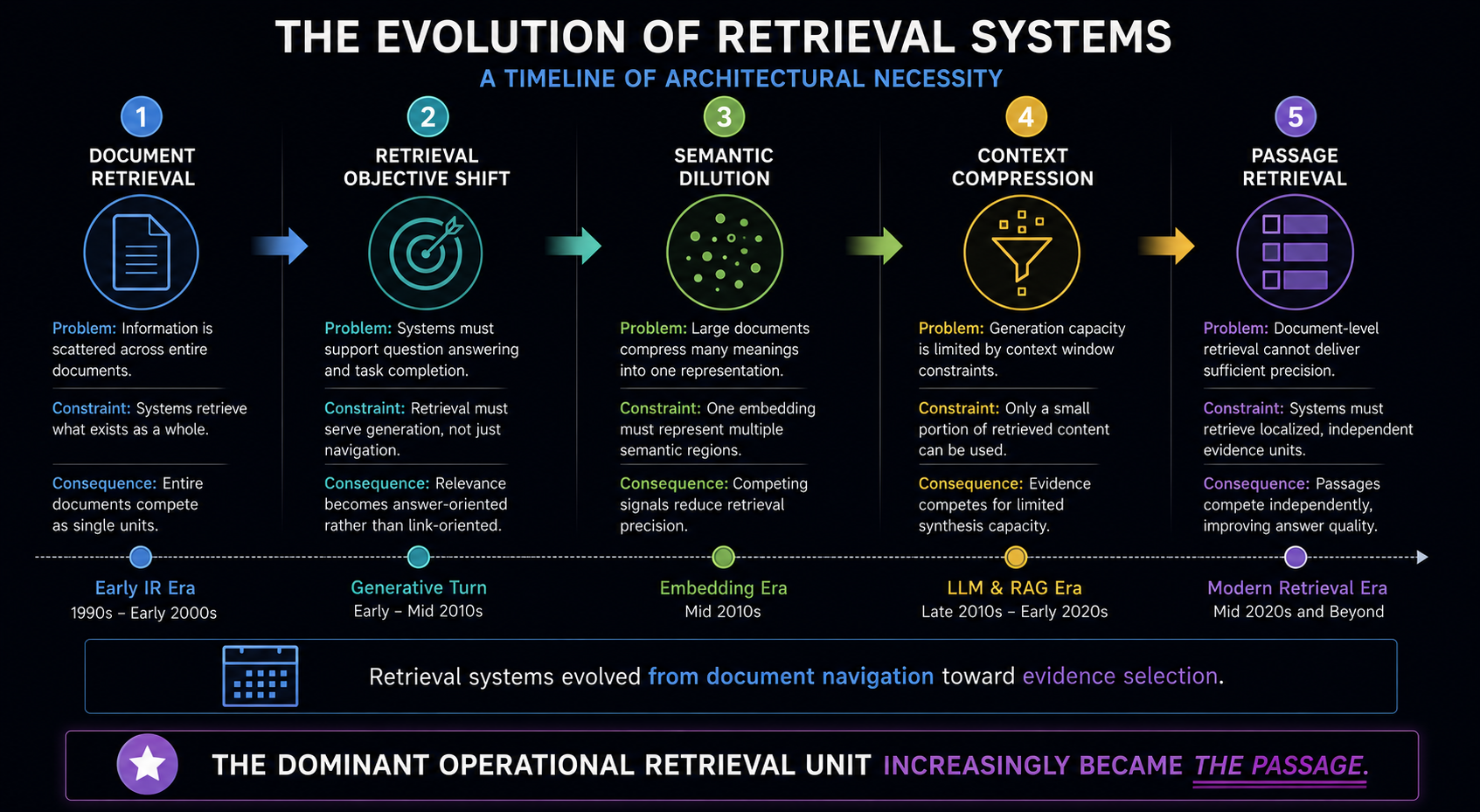
Modern AI systems retrieve passages instead of pages because the architectural assumptions underlying document-level retrieval no longer satisfy the requirements of retrieval systems designed for synthesis rather than navigation. Passage Retrieval emerged because it better matches the computational realities of dense representations, constrained context allocation, and evidence-driven generation pipelines.
That conclusion, however, exposes the next architectural question. Once retrieval depends on Passage Retrieval Units rather than complete documents, documents can no longer function solely as monolithic retrieval objects. They must instead provide retrieval systems with independently retrievable Passage Retrieval Units capable of participating directly in modern retrieval pipelines. How documents acquire those independently retrievable Passage Retrieval Units becomes the next engineering problem.
Series Navigation Block
Retrieval Systems Series
Part 1
Why AI Systems Retrieve Passages Instead Of Pages (Current Article)
↓
Part 2
How AI Systems Transform Documents Into Retrievable Evidence (Coming Soon)
↓
Part 3
How Modern Retrieval Pipelines Select Evidence Before AI Generates Answers (Coming Soon)
FAQ Section:
FAQ 1: Why do AI systems retrieve passages instead of entire pages?
AI systems retrieve passages instead of entire pages because Passage Retrieval Units provide higher Evidence Density and stronger query alignment than complete Document Retrieval Units. Traditional Document Retrieval systems optimized for locating relevant documents, whereas modern retrieval systems increasingly optimize for locating Evidence capable of supporting answer generation. Entire documents frequently contain multiple Semantic Regions, navigational structures, redundant context, and semantically unrelated information that dilute Retrieval Visibility for highly relevant Evidence.
Architecturally, retrieval systems operate within finite context windows and limited synthesis capacity. Passage Retrieval therefore isolates Passage Retrieval Units and Evidence Spans rather than relying on complete Document Retrieval Units. Smaller Retrieval Units preserve stronger semantic boundaries, reduce Semantic Dilution, and survive Context Compression more effectively.
The implication is that Passage Retrieval enables localized Evidence to compete independently for Retrieval Visibility, making it a more efficient retrieval object for synthesis-oriented systems than complete webpages.
FAQ 2: What is Passage Retrieval?
Passage Retrieval is a retrieval architecture that indexes and retrieves localized Passage Retrieval Units instead of treating entire documents as single Document Retrieval Units. The architecture isolates smaller Semantic Regions and allows those regions to compete independently for Retrieval Visibility. As a result, highly relevant Evidence Spans can surface even when surrounding portions of the original document are less relevant to a query.
Architecturally, Passage Retrieval changes Retrieval Granularity. Document Retrieval evaluates an entire document through a single retrieval representation, whereas Passage Retrieval assigns retrieval representations to smaller Retrieval Units. This preserves stronger semantic boundaries and improves alignment between retrieved Evidence and query intent.
The implication is that retrieval systems become increasingly focused on Evidence selection rather than document selection. By reducing Semantic Dilution and preserving higher Evidence Density, Passage Retrieval improves the ability of retrieval systems to surface localized Evidence that remains useful within Context Compression constraints.
FAQ 3: How is Passage Retrieval different from Document Retrieval?
Passage Retrieval differs from Document Retrieval because Passage Retrieval retrieves localized Passage Retrieval Units independently, whereas Document Retrieval retrieves entire documents as single Document Retrieval Units. The difference is determined by Retrieval Granularity.
In Document Retrieval architectures, multiple Semantic Regions are represented together within a single retrieval representation. Relevant Evidence therefore competes alongside unrelated or weakly related content contained within the same document. Passage Retrieval instead allows localized Semantic Regions and Evidence Spans to compete independently for Retrieval Visibility, preserving stronger semantic alignment with the query.
Architecturally, Document Retrieval treats the document as the primary Retrieval Unit, while Passage Retrieval treats Passage Retrieval Units as the primary Retrieval Unit. This shifts retrieval behavior from broad document-level relevance toward evidence-level relevance.
The implication is that Passage Retrieval preserves higher Evidence Density, improves query alignment, and reduces Semantic Dilution, allowing highly relevant Evidence to surface more reliably than under document-level retrieval.
FAQ 4: Why is whole-page retrieval inefficient for AI systems?
Whole-page retrieval is inefficient for AI systems because complete Document Retrieval Units often contain large amounts of content that consume synthesis capacity while contributing relatively little usable Evidence. A document may contain a small number of highly relevant Evidence Spans surrounded by navigational structures, redundant explanations, mixed topics, and low Evidence Density Semantic Regions.
The mechanism is Context Compression. Retrieved information competes for limited representation inside finite context windows, making retrieval efficiency dependent on how much useful Evidence can be preserved within constrained synthesis environments.
Architecturally, large Document Retrieval Units distribute relevant Evidence across multiple Semantic Regions, forcing highly relevant information to compete against surrounding contextual mass. Passage Retrieval addresses this limitation by isolating localized Evidence into smaller Passage Retrieval Units with higher Evidence Density and stronger Retrieval Visibility.
The implication is that retrieval quality becomes increasingly dependent on the efficient allocation of synthesis capacity, making Passage Retrieval a more effective retrieval architecture than whole-page retrieval for synthesis-oriented systems.
FAQ 5: What is Semantic Dilution in dense retrieval systems?
Semantic Dilution is the reduction of Retrieval Visibility that occurs when multiple Semantic Regions are compressed into a single retrieval representation. As semantically distinct information is aggregated within the same Document Retrieval Unit, highly relevant Evidence becomes less distinguishable from surrounding content.
The mechanism emerges because dense retrieval systems depend on precise semantic alignment between queries and retrieval representations. When multiple Semantic Regions share one representation, localized Evidence loses semantic distinctiveness and becomes harder to retrieve accurately.
Architecturally, larger Document Retrieval Units increase representational competition by forcing multiple concepts to coexist within the same retrieval object. Passage Retrieval reduces Semantic Dilution by allowing smaller Passage Retrieval Units to preserve independent semantic boundaries.
The implication is that Semantic Dilution weakens retrieval precision by reducing the visibility of localized Evidence, making Passage Retrieval more effective than document-level retrieval in dense retrieval systems.
FAQ 6: How do context windows influence retrieval behavior?
Context windows influence retrieval behavior by limiting the amount of retrieved information that can participate effectively in synthesis. Because synthesis capacity is finite, retrieval systems must prioritize Evidence that provides the greatest value within available context allocation.
The mechanism is that retrieved information competes for limited representational space. Large Document Retrieval Units often contain highly relevant Evidence alongside low Evidence Density Semantic Regions that consume context resources without contributing equivalent retrieval value.
Architecturally, retrieval systems increasingly favor Retrieval Units that concentrate useful Evidence while minimizing contextual overhead. Passage Retrieval aligns with this requirement by retrieving smaller Passage Retrieval Units that preserve stronger Evidence Density.
The implication is that context windows encourage retrieval systems to prioritize localized Evidence, increasing the effectiveness of Passage Retrieval relative to Document Retrieval.
FAQ 7: What is Context Compression?
Context Compression is the retrieval pressure created by finite context windows that forces retrieval systems to maximize useful Evidence within limited synthesis capacity. Retrieved information must compete for scarce context allocation rather than entering generation environments without constraint.
The mechanism arises because every retrieved Retrieval Unit occupies synthesis capacity. Large Document Retrieval Units frequently contain low Evidence Density Semantic Regions that consume context resources while contributing relatively little useful Evidence.
Architecturally, Context Compression shifts retrieval optimization toward Evidence Density and context efficiency. Passage Retrieval addresses this constraint by isolating smaller Passage Retrieval Units that concentrate relevant Evidence and reduce contextual overhead.
The implication is that retrieval quality depends not only on relevance but also on how efficiently retrieved Evidence uses available synthesis capacity, making Context Compression a primary driver of Passage Retrieval architectures.
FAQ 8: Why is localized Evidence more effective than whole-document Evidence in modern retrieval systems?
Localized Evidence is more effective than Evidence contained within complete Document Retrieval Units because localized Evidence preserves higher Evidence Density, stronger query alignment, and greater Retrieval Visibility than complete Document Retrieval Units. Whole documents frequently contain multiple Semantic Regions and semantically unrelated information that compete with relevant Evidence during retrieval.
The mechanism is driven by Semantic Dilution and Context Compression. Relevant Evidence becomes less distinguishable when multiple Semantic Regions share the same retrieval representation, and large Document Retrieval Units consume synthesis capacity with surrounding content that contributes limited retrieval value.
Architecturally, Passage Retrieval allows localized Passage Retrieval Units containing Evidence to compete independently rather than through a single document-level retrieval representation.
The implication is that localized Evidence survives retrieval and synthesis constraints more effectively than Evidence contained within whole Document Retrieval Units, making Passage Retrieval better aligned with modern retrieval systems.
FAQ 9: What is Dense Passage Retrieval (DPR)?
Dense Passage Retrieval (DPR) is a Passage Retrieval architecture that retrieves Passage Retrieval Units through dense semantic representations rather than document-level retrieval representations. DPR operationalized the idea that localized Semantic Regions can be retrieved through independently indexed Passage Retrieval Units within dense retrieval systems.
The mechanism involves encoding queries and Passage Retrieval Units separately and retrieving passages through semantic similarity. Instead of requiring an entire Document Retrieval Unit to compete as a single retrieval object, DPR allows localized Evidence to compete independently for Retrieval Visibility.
Architecturally, DPR shifts retrieval competition from Document Retrieval Units toward Passage Retrieval Units. This reduces Semantic Dilution because individual Semantic Regions preserve stronger semantic boundaries and maintain closer alignment with query intent than broader document-level representations.
The implication is that DPR demonstrated the effectiveness of passage-level retrieval within dense retrieval systems, reinforcing the transition from document-centric retrieval toward retrieval architectures built around localized Evidence.
FAQ 10: How does Passage Retrieval improve retrieval precision?
Passage Retrieval improves retrieval precision by allowing localized Evidence to compete independently for Retrieval Visibility rather than requiring all information within a Document Retrieval Unit to compete through a single retrieval representation. This produces stronger alignment between queries and retrieved Evidence.
The mechanism is the reduction of Semantic Dilution. When multiple Semantic Regions are combined within a Document Retrieval Unit, highly relevant Evidence must compete against unrelated or weakly related content. Passage Retrieval isolates smaller Passage Retrieval Units, preserving semantic distinctiveness and improving retrieval accuracy.
Architecturally, Passage Retrieval increases Retrieval Granularity by shifting retrieval competition from documents to localized Semantic Regions. Individual Evidence Spans therefore participate in retrieval through Passage Retrieval Units rather than being absorbed into broader document-level representations.
The implication is that retrieval systems can identify highly relevant Evidence more reliably, resulting in stronger query alignment, higher Evidence Density, and improved retrieval precision.
FAQ 11: Is Passage Retrieval used in Retrieval-Augmented Generation (RAG)?
Yes. Passage Retrieval is commonly used within Retrieval-Augmented Generation (RAG) systems because RAG architectures require retrieved Evidence that can be efficiently incorporated into synthesis workflows. Passage Retrieval Units provide a more effective retrieval object for this purpose than complete Document Retrieval Units.
The mechanism is that retrieved information must compete within finite context windows and limited synthesis capacity. Large documents often contain multiple Semantic Regions and substantial contextual overhead, while localized Evidence provides higher Evidence Density and stronger query alignment.
Architecturally, RAG systems operate by combining retrieval with answer generation. Passage Retrieval supports this architecture by supplying localized Evidence and Evidence Spans that can survive Context Compression more effectively than complete documents.
The implication is that Passage Retrieval aligns naturally with the operational requirements of RAG systems because retrieval quality increasingly depends on delivering highly relevant Evidence rather than broadly relevant documents.
FAQ 12: Why did traditional search engines retrieve pages instead of passages?
Traditional search engines retrieved pages instead of passages because webpages functioned as the primary Document Retrieval Units within a navigation-oriented retrieval architecture. Retrieval systems were designed to locate relevant documents, while users were responsible for identifying the relevant Evidence contained within those documents.
The mechanism was tied to the retrieval objective. Traditional retrieval systems optimized for document discovery, document ranking, and navigational efficiency rather than direct Evidence selection. A retrieved page served as a destination object from which users manually located relevant information.
Architecturally, indexing, ranking, and retrieval systems were organized around Document Retrieval Units. Pages represented stable and computationally manageable retrieval objects, making document-level retrieval the dominant retrieval model.
The implication is that page-level retrieval remained effective while retrieval primarily supported navigation. Passage Retrieval emerged later as retrieval systems increasingly required localized Evidence rather than complete documents.
References
-
Robertson, S., & Zaragoza, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval. Source
-
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Source
-
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W. (2020). Dense Passage Retrieval for Open-Domain Question Answering. Source
-
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Source
-
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts. Source